Pandas 数据合并与重塑
pandas 数据的行更新、表合并等操作,一般用到的方法有 concat、join、merge。
concat
concat 函数是在 pandas 底下的方法,可以将数据根据不同的轴作简单的融合
pd.concat(objs,
axis=0,
join='outer',
join_axes=None,
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False
)
参数说明
objs: series,dataframe或者是panel构成的序列lsitaxis: 需要合并链接的轴,0是行,1是列join:连接的方式 inner,或者outer
相同字段的表首尾相接

import pandas as pd
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
# 现将表构成list,然后在作为concat的输入
frames = [df1, df2, df3]
result = pd.concat(frames)
print(result)
参数key
要在相接的时候在加上一个层次的 key来识别数据源自于哪张表,可以增加 key参数
result = pd.concat(frames, keys=['x', 'y', 'z'])
'''
A B C D
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
'''
横向表拼接(行对齐)
参数 axis
当 axis = 1 的时候,concat 就是行对齐,然后将不同列名称的两张表合并
result = pd.concat([df1, df4], axis=1)

参数 join
加上 join参数的属性,如果为inner得到的是两表的交集,如果是outer,得到的是两表的并集。(行索引相同的行)
result = pd.concat([df1, df4], axis=1, join='inner')

参数 join_axes
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据 df1 表对齐数据,就会保留指定的df1表的轴,然后将 df4 的表与之拼接
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])

参数 ignore_index
如果两个表的 index 都没有实际含义,使用ignore_index参数,置true,合并的两个表就会根据列字段对齐,然后合并。最后再重新整理一个新的 index。
result=pd.concat([df1,df4],ignore_index=True)

合并的同时增加区分数据组
前面提到的keys参数可以用来给合并后的表增加key来区分不同的表数据来源
直接用key参数实现
result = pd.concat(frames, keys=['x', 'y', 'z'])
'''
A B C D
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
'''
传入字典来增加分组键
pieces = {'x': df1, 'y': df2, 'z': df3}
result = pd.concat(pieces)
'''
A B C D
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
'''
表格列字段不同的表合并
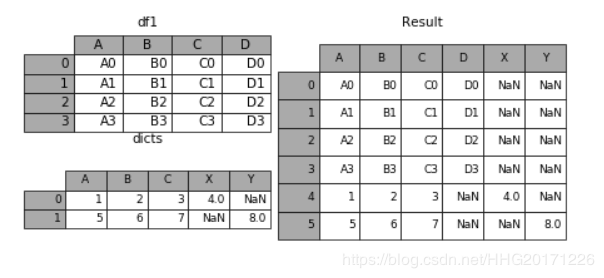
如果遇到两张表的列字段本来就不一样,但又想将两个表合并,其中无效的值用nan来表示。那么可以使用 ignore_index来实现。
dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
{'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
result = df1.append(dicts, ignore_index=True)
append
DataFrame.append(other,
ignore_index=False,
verify_integrity=False,
sort=None
)
- other:DataFrame、series、dict、list这样的数据结构
- ignore_index:默认值为False,如果为True则不使用index标签
- verify_integrity :默认值为False,如果为True当创建相同的index时会抛出ValueError的异常
- sort:boolean,默认是None,该属性在pandas的0.23.0的版本才存在。
append是 series 和 dataframe的方法,使用它就是默认沿着列进行凭借(axis = 0,列对齐)
result = df1.append(df2)

append添加字典
import pandas as pd
data = pd.DataFrame()
a = {"x":1,"y":2}
data = data.append(a,ignore_index=True)
print(data)
x y
0 1.0 2.0
append添加series
如果不添加ignore_index=True,会报错提示TypeError: Can only append a Series if ignore_index=True or if the Series has a name,如果不添加ignore_index=True,也可以改成以下代码
import pandas as pd
data = pd.DataFrame()
series = pd.Series({"x":1,"y":2},name="a")
data = data.append(series)
print(data)
x y
0 1.0 2.0
append添加list
data = pd.DataFrame()
a = [1,2,3]
data = data.append(a)
print(data)
0
0 1
1 2
2 3
如果list是一维的,则是以列的形式来进行添加,如果list是二维的则是以行的形式进行添加的 ,如果是三维的则只添加一个值
merge
merge(left,
right,
how='inner',
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=True,
suffixes=('_x', '_y'),
copy=True,
indicator=False
)
on:列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。left_on:左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。right_on:右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。left_index/ right_index: 如果是 True 的 haunted 以 index 作为对齐的keyhow:数据融合的方法。sort:根据 dataframe 合并的 keys 按字典顺序排序,默认是,如果置false可以提高表现。
merge的默认合并方法: merge 用于表内部基于 index-on-index 和 index-on-column(s) 的合并,但默认是基于 index 来合并。
通过on指定数据合并对齐的列
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on=['key1', 'key2'])
'''
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
'''
没有指定how的话默认使用inner方法。
how的方法有:
left
只保留左表的所有数据
result = pd.merge(left, right, how='left', on=['key1', 'key2'])

right
只保留右表的所有数据
result = pd.merge(left, right, how='right', on=['key1', 'key2'])

outer
保留两个表的所有信息
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])

inner
只保留两个表中公共部分的信息
result = pd.merge(left, right, how='inner', on=['key1', 'key2'])

suffix后缀参数
如果和表合并的过程中遇到有一列两个表都同名,但是值不同,合并的时候又都想保留下来,就可以用suffixes给每个表的重复列名增加后缀。
result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])

另外还有lsuffix 和 rsuffix分别指定左表的后缀和右表的后缀。
join
dataframe 内置的join方 法是一种快速合并的方法。它默认以index 作为对齐的列。
join中的 how 参数和 merge 中的how 参数一样,用来指定表合并保留数据的规则。主要用于索引上的合并
join(other,
on=None,
how='left',
lsuffix='',
rsuffix='',
sort=False)
参数 on
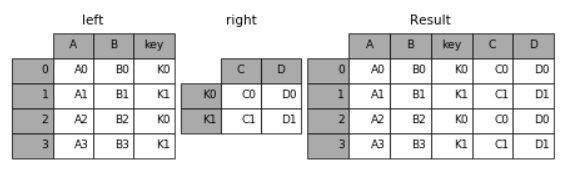
在实际应用中如果右表的索引值正是左表的某一列的值,这时可以通过将 右表的索引 和 左表的列 对齐合并这样灵活的方式进行合并。
In [59]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [60]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [61]: result = left.join(right, on='key')
插入函数 insert
DataFrame.insert(loc, column, value, allow_duplicates=False)
在指定列插入数据
Raises a ValueError if column is already contained in the DataFrame, unless allow_duplicates is set to True.
Parameters:
loc: int 使用整数定义列数据插入的位置,必须是0到columns列标签的长度 Insertion index. Must verify 0 <= loc <= len(columns)column: string, number, or hashable object # 可选字符串、数字或者object;列标签名 label of the inserted columnvalue: int, Series, or array-like # 整数、Series或者数组型数据allow_duplicates: bool, optional # 可选参数,如果dataframe中已经存在某列,将allow_duplicates置为true才可以将指定得列插入。
实例详解:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape(4,3)
,columns=['a','b','c'])
df
a b c
0 0 1 2
1 3 4 5
2 6 7 8
3 9 10 11
在第二列插入数据:
df.insert(1,'d',np.ones(4))
df
a d b c
0 0 1.0 1 2
1 3 1.0 4 5
2 6 1.0 7 8
3 9 1.0 10 11
如果没有设定 allow_duplicates = True,此时如果添加的列已经存在,则会报错:
df.insert(1,'d',np.ones(4))
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-7-ee16a5e00623> in <module>
----> 1 df.insert(1,'d',np.ones(4))
D:\Application\Anaconda3\envs\pycharm\lib\site-packages\pandas\core\frame.py in insert(self, loc, column, value, allow_duplicates)
3494 self._ensure_valid_index(value)
3495 value = self._sanitize_column(column, value, broadcast=False)
-> 3496 self._data.insert(loc, column, value, allow_duplicates=allow_duplicates)
3497
3498 def assign(self, **kwargs) -> "DataFrame":
D:\Application\Anaconda3\envs\pycharm\lib\site-packages\pandas\core\internals\managers.py in insert(self, loc, item, value, allow_duplicates)
1171 if not allow_duplicates and item in self.items:
1172 # Should this be a different kind of error??
-> 1173 raise ValueError(f"cannot insert {item}, already exists")
1174
1175 if not isinstance(loc, int):
ValueError: cannot insert d, already exists
因此,如果是添加的列已经存在,如下处理:
df.insert(1,'d',np.ones(4),allow_duplicates=True) #allow_duplicates=True
df
a d d b c
0 0 1.0 1.0 1 2
1 3 1.0 1.0 4 5
2 6 1.0 1.0 7 8
3 9 1.0 1.0 10 11